
<lora:learn:0.6>,sitting,zettai ryouiki,black hair,dress,short sleeves,breasts,asymmetrical wings,looking at viewer,:o,arm support,touhou,red eyes,snake,wings,blush,solo,short hair,red wings,black thighhighs
Introduction
In this quick post, I'm going to share my worfkflow to create a LoRA with a single picture. If you've been following my work from the very start, you'll know that my first LoRAs were mainly traine on single pictures (see my 1-shot series on CivitAI).
The idea of this post is not to explain in detail each parameter available, but to give you a quick setup to train your own LoRAs.
Kohya GUI
The UI I'm going to use for the training is Kohya_ss, which is one of the most used at the moment.
I'm not going to do a step-by-step setup tutorial in this post (you can find a lot of tutorials about it just by searching on Bing), but you can learn more about how to install it here:
bmaltais/kohya_ss (github.com)
After you've installed the UI just launch it using the commands explained here:
bmaltais/kohya_ss (github.com)
Getting a training picture
The first step is (obviously) to get a picture to train the LoRA on. In my workflow I try to avoid training LoRAs on non-public domain content, so for this example I'm going to use Bing.com/create (but you can use what you prefer).
After we've opened the page, we can now use a prompt. In the below examples I've seen one that it seems interesting:
Let's change its prompt to fit what I want to create:
woman portrait, sufganiot, byzantine Japanese woodblock scene, in viennese secession style, gilded, chromatic, whimsical, hanukkah
And here's the batch of pictures:
From this batch I'd like to train a LoRA based on the picture on the bottom right. Keep in mind that when training a LoRA on a single picture, it will be highly biased towards each characteristic of the picture (so in this case it will probably be biased towards candelabras and hair decorations).
Setting up the folder
To train the model you'll need to create a folder with a specific structure:
| model-name
| -- img
| ---- pic-folders
| -- model
- model-name: This can be anything you like. For this example I'm going to call it learn_final (because for some reason I've called all my project folders something_final)
- img: This is the folder where you'll put the pictures subfolders
- pic-folders: This can be one or more folders (in our simple case it will be just one). The name of this folder should be the number of the repetitions, underscore, a list of tags divided by commas. For this example I'm going to use 40 repetitions with just an "inzaniak" tag (so the folder will be 40_inzaniak). If I'm not training a specific concept I prefer to keep just the "inzaniak" tag without adding anything else. If you want, you can also add a .txt file in the same folder (keeping the same name of the picture), with a list of specific tags related to the picture.
- model: This is the folder, where the model will be saved
So in my case this is the actual folder structure:
\learn_final
├───img
│ └───40_inzaniak
│ OIG.jpg
│
├───log
└───model
Remember to copy the picture you've downloaded in the first step to the picture folder!
Setting up the UI
The first thing we need to do is to go to the LoRA tab:
Once you are in the tab we need to do the following:
- Select the source model
- Select the folders we've created
- Choose the parameters for the training
Bonus/Super patrons can find the pre-configured train file here:
PATREONIf you use this config file, you'll only need to follow the first two points (and change the batch size based on your GPU VRAM).To load the config file you can click on open in the "Configuration file" section (be sure to have the LoRA tab selected!):
Selecting the source model
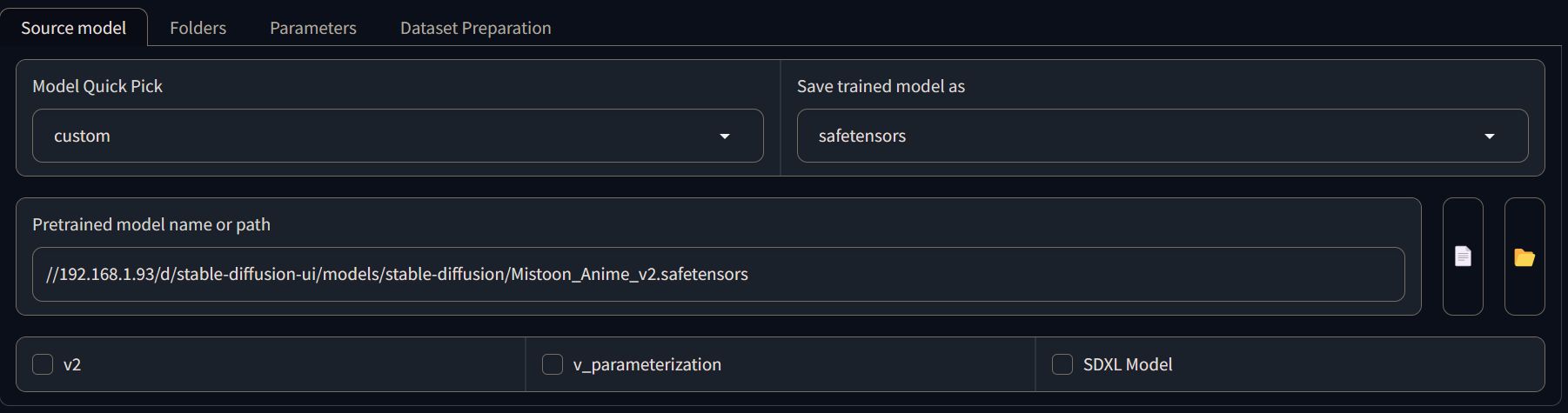
The first thing to do is to select the base model to use for the training. You usually have two choices:
- Using the base SD model. This usually is the best way to make the LoRA compatible with every model, but you can lose some quality if you want to use it with a specific checkpoint.
- Using the checkpoint you are going to mainly use. This is what I do, I select my Mistoon_Anime_v2 model and use that as a base.
Once you've chosen the model you'll also have the possibility to specify if it is a v2 or SDXL model.
Select the folders
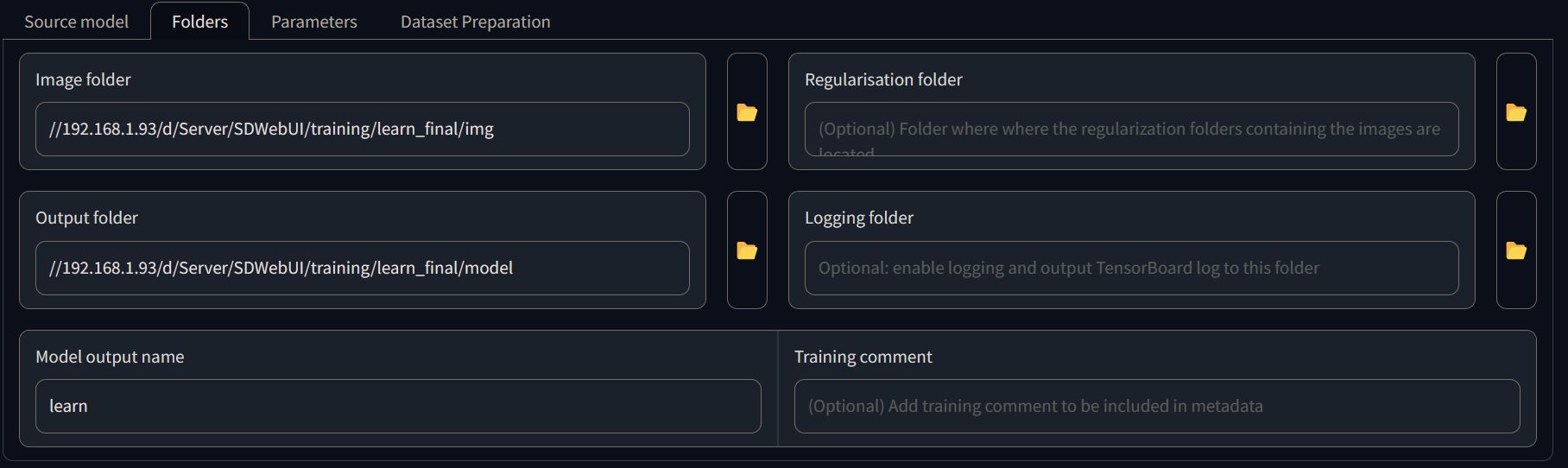
Go to the folders tab and insert into the "Image Folder" and "Output Folder" the related path. You'll also need to specify the name for the model.
Selecting the parameters
I'm not going into detail on what each parameter do (as it will take a lot of time and it's out-of-scope for this post), but here's what I'm using right now: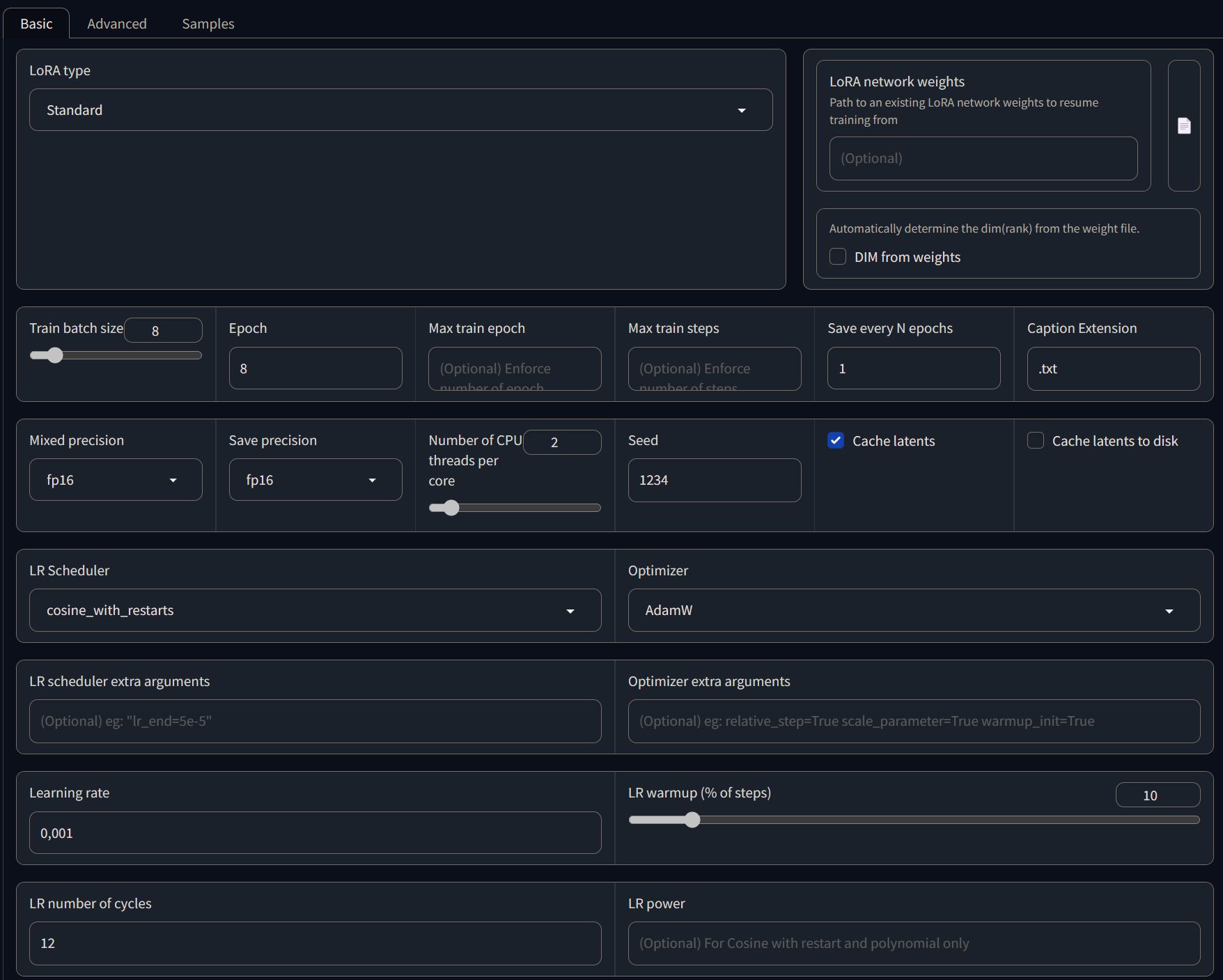
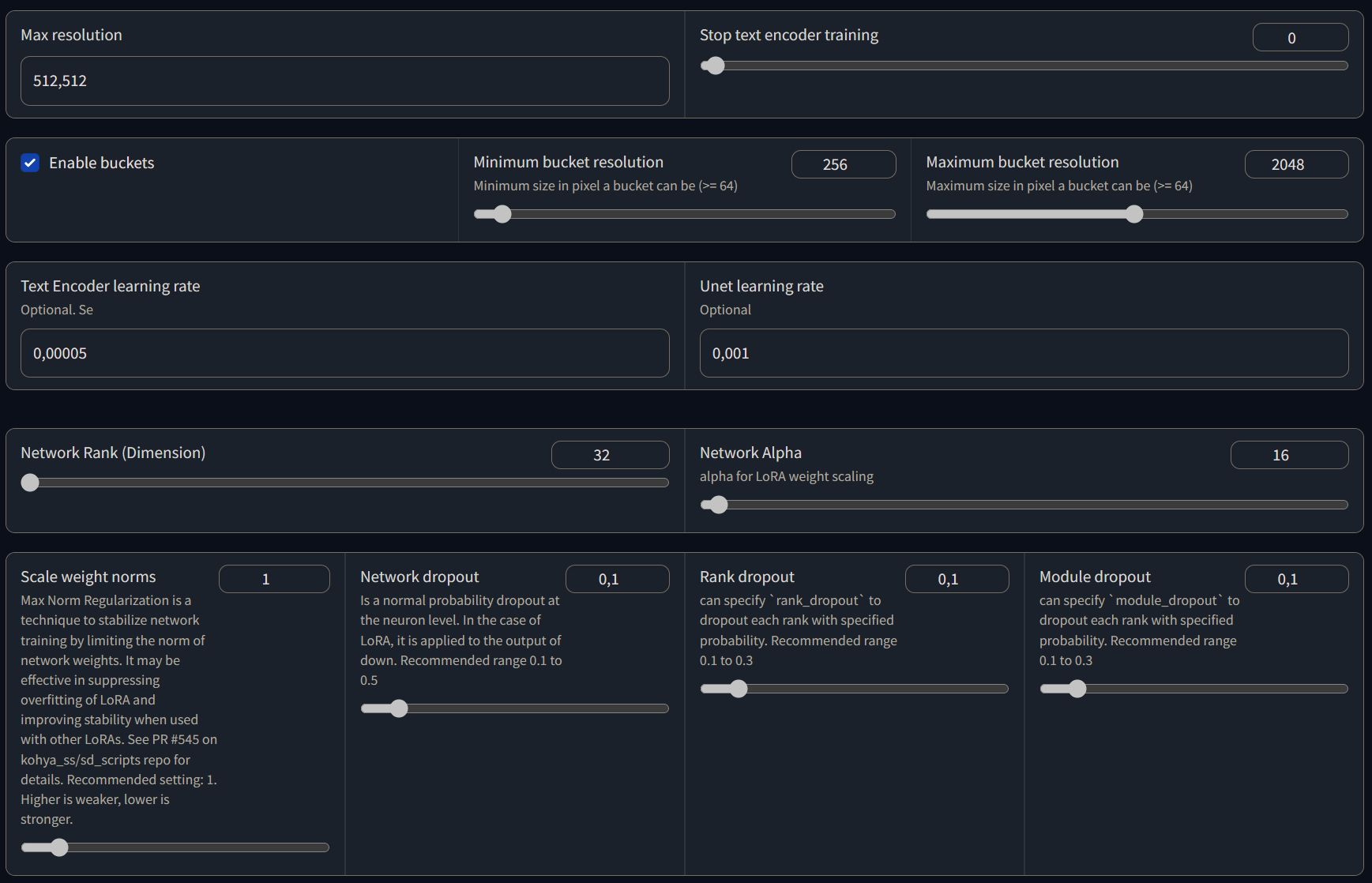
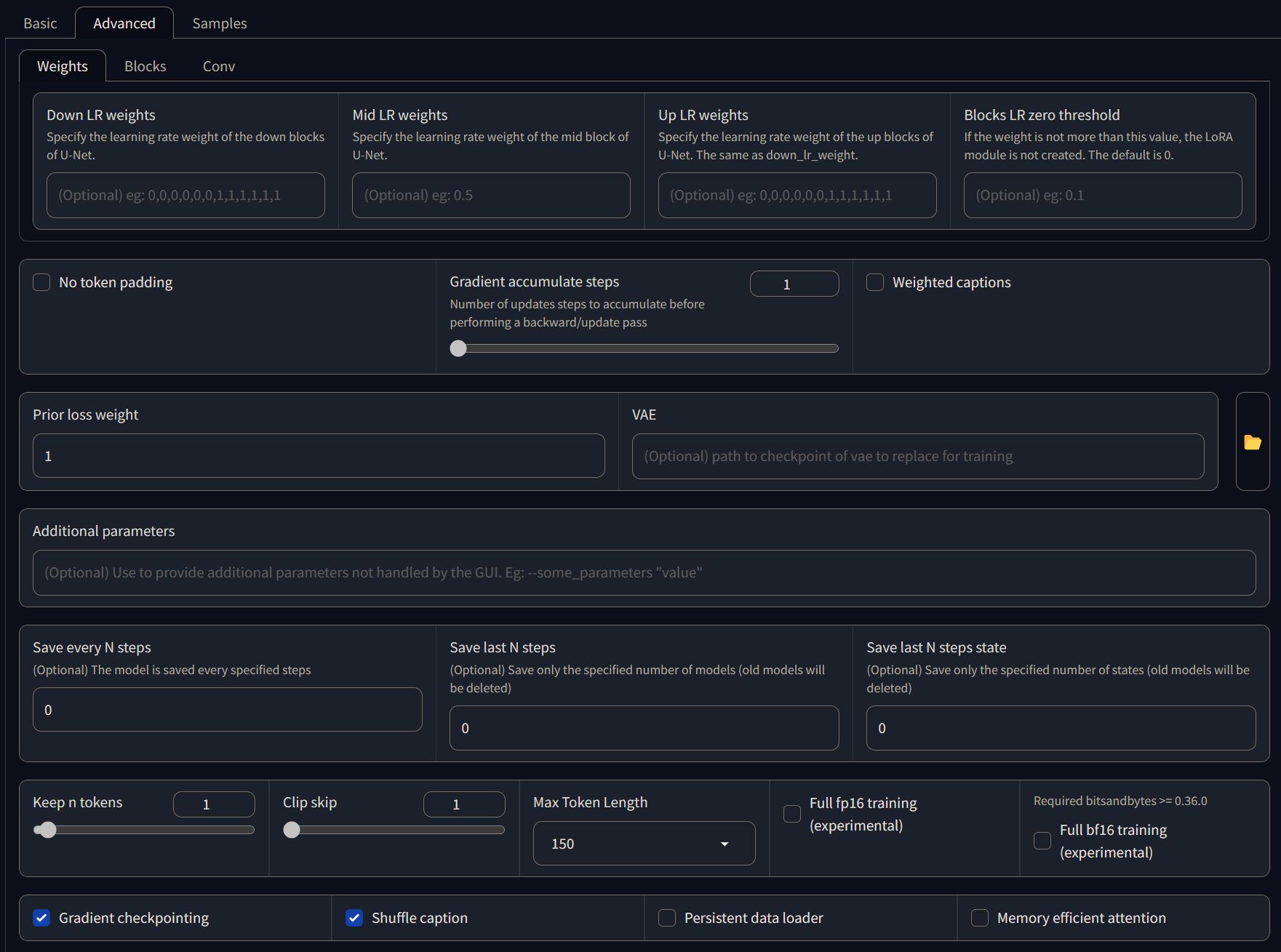
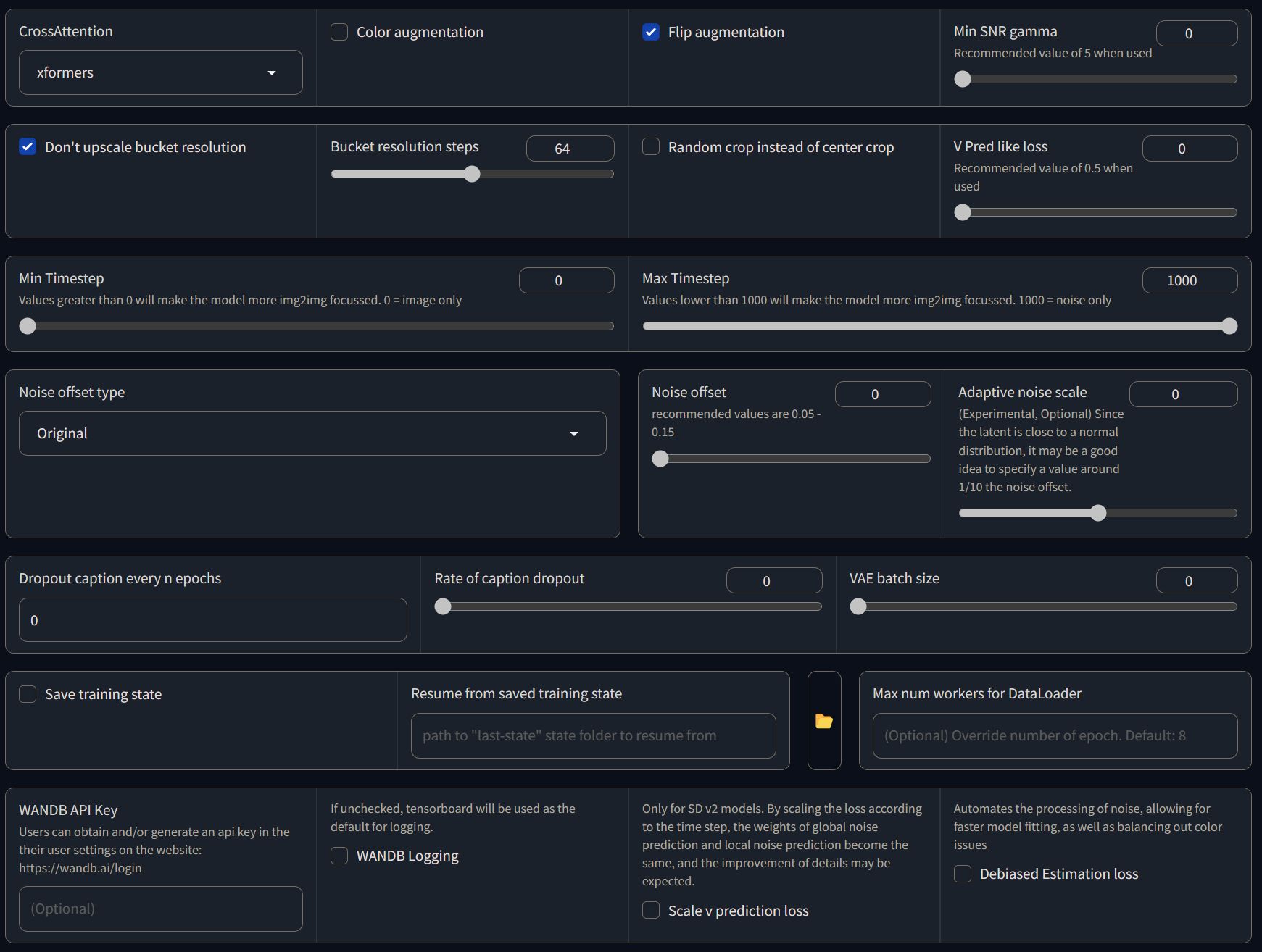
Keep in mind that I'm using Kohya_ss version: v22.3, so this list could change in the future.
Once you've setup the parameters as mine you can save them by going to the top of the page and clicking "Save as" in the "Configuration file" section:
Before running the training, you'll probably need to check the following:
- Train Batch Size: this changes how many steps are done in parallel. This makes the training quicker, but also uses a lot of VRAM. I'm using a 16gb card and I'm able of doing a batch size of 8.
- Epoch: This is the number of epochs you are running the training for. I save the model each epoch, so I can choose the best version. Usually it takes at least 4 epochs to have something nice, while the further you go the more you'll get closer to have the same original picture.
Now you can run the training process. Depending on your hardware, epochs and batch size it could take a while (using my settings and a 4080 requires about 8/9 minutes)
Testing the LoRA
Once you've finished training the LoRA, you should now see the trained models inside of the model folder. You can copy every .safetensors file and paste it in your LoRA folder.
Now you just need to run a prompt as you usually do and experiment with the different epochs.
Here's a bunch of pictures generated with Ranbooru with the 8 epochs version of the LoRA and a weight of 1.0:
Support Me
I've started developing custom models for myself a few months ago just to check out how SD worked, but in the last few months it has become a new hobby I like to practice in my free time. All my checkpoints and LoRAs will always be released for free on Patreon or CivitAI, but if you want to support my work and get early access to all my models feel free to check out my Patreon:
https://www.patreon.com/Inzaniak
If you want to support my work for free, you can also check out my music/art here: